- POSTECH에서 제공하는 MOOC 중, 빅데이터분석과 R프로그래밍 Ⅰ 과정입니다.
1. R 데이터 생성
파일 불러들이기
csv
brain <- read.csv(“week3_2/brain2210.csv”, header=T)
xls
- *.xls 파일인 경우, 데이터를 csv(comma separated value)로 저장한
다음 read.csv 함수를 사용해 r로 불러들이는 게 편리 - readxl로도 가능함
- txt
파일을 부를 이름 <- read.table(file = "파일명.txt, na = " ", header = TRUE)데이터 저장 폴더
- 데이터와 프로그램 저장 폴더 지정
- 폴더 이름은 영문으로 생성할 것
- r 프로그램의 기본 경로 지정하는 명령어
# change working directory
#set working directory
setwd("경로")
# check the current working directory
getwd()데이터와 변수 이름
attach를 사용하면 정의된 파일 이름 입력 없이 바로 항목 조회가 가능
# attach 사용
attach(brain)
# 원래대로라면
table(brain$sex)
##
## f m
## 77 108
# attach를 쓰고 나면
table(sex)
## sex
## f m
## 77 1082. R 데이터 활용 Ⅰ
데이터 추출_subset
- subset(데이터 이름, 조건)
예제 1. brain 데이터에서 female만 있는 subset 데이터 생성
brainf <- subset(brain, sex = "f")
mean(brainf$wt)
## [1] 1206.822예제 2. brain 데이터에서 wt < 1300 이하인 데이터 생성
# subset with wt < 1300
brain1300 <- subset(brain, brain$wt < 1300)
# same subset of brain1300
# brain1300 <- subset(brain, !brain@wt => 1300)
summary(brain1300)
## wt sex
## Min. : 915 Length:138
## 1st Qu.:1074 Class :character
## Median :1155 Mode :character
## Mean :1145
## 3rd Qu.:1230
## Max. :1289
# subset with female
# brainf <- subset(brain, sex = "f")
brainf <- subset(brain, sex == "f")
mean(brainf$wt)
## [1] 1117.169
sd(brainf$wt)
## [1] 98.97094
# subset with male
brainm <- subset(brain, sex == "m")
mean(brainm$wt)
## [1] 1270.741
sd(brainm$wt)
## [1] 129.22요약통계치 (그룹별)_aggregate
- aggregate(변수~그룹, 데이터, 함수)
# 'aggregate' for statistics by group
aggregate(wt~sex, data = brain, FUN = mean)
## sex wt
## 1 f 1117.169
## 2 m 1270.741
aggregate(wt~sex, data = brain, FUN = sd)
## sex wt
## 1 f 98.97094
## 2 m 129.21997- 추출한 데이터의 활용 (그룹별 히스토그램)
# histogram for female and male
# 2*2 multiple plot
par(mfrow=c(2,2))
brainf<-subset(brain,brain$sex=='f')
hist(brainf$wt, breaks = 12,col = "green",cex=0.7, main="Histogram (Female)" ,xlab="brain weight")
# subset with male
brainm<-subset(brain,brain$sex=='m')
hist(brainm$wt, breaks = 12,col = "orange", main="Histogram with (Male)" , xlab="brain weight")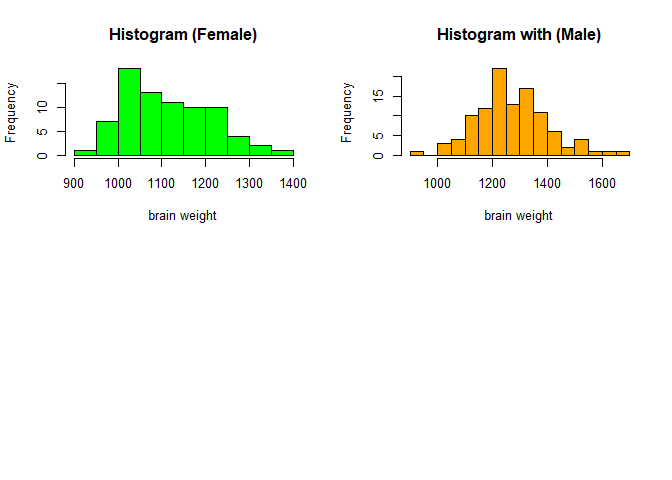
- 추출한 데이터의 활용
# histogram with same scale
hist(brainf$wt, breaks = 12,col = "green",cex=0.7, main="Histogram with Normal Curve (Female)" , xlim=c(900,1700),ylim=c(0,25), xlab="brain weight")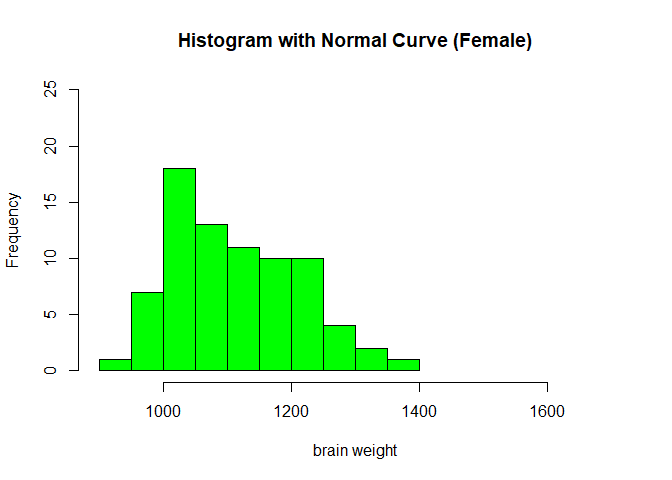
hist(brainm$wt, breaks = 12,col = "orange", main="Histogram with Normal Curve (Male)" , xlim=c(900,1700), ylim=c(0,25),xlab="brain weight")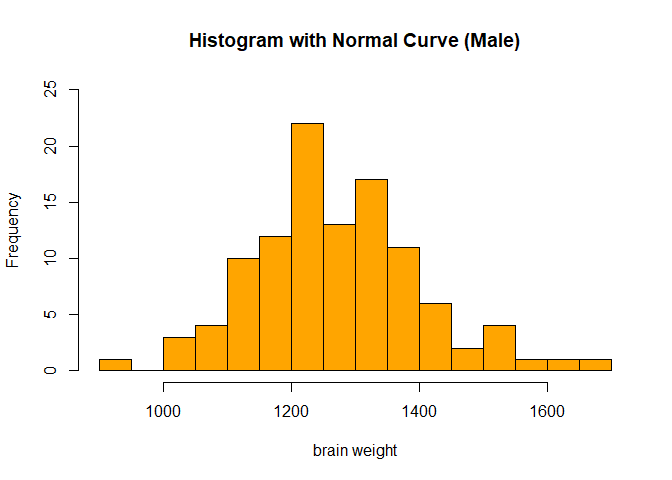
- csv로 내보내기
# plot margin
# par(mar=c(2,2,2,2))
# export csv file - write out to csv file
write.table(brainf,file="week3_2/brainf.csv", row.names = FALSE, sep=",", na=" ")
write.csv(brainf,file="week3_2/brainf.csv", row.names = FALSE)
# export txt file
write.table(brainm, file="week3_2/brainm.txt", row.names = FALSE, na=" ")- 퀴즈
brain1000 <- subset(brain, brain$wt < 1000) brain1000
table(brain1000)
3. R 데이터 활용 Ⅱ
dplyr 패키지
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
car <- read.csv("week3_3/autompg.csv")
head(car)
## mpg cyl disp hp wt accler year origin carname
## 1 18 8 307 17 3504 12.0 70 1 chevrolet chevelle malibu
## 2 15 8 350 35 3693 11.5 70 1 buick skylark 320
## 3 18 8 318 29 3436 11.0 70 1 plymouth satellite
## 4 16 8 304 29 3433 12.0 70 1 amc rebel sst
## 5 17 8 302 24 3449 10.5 70 1 ford torino
## 6 15 8 429 42 4341 10.0 70 1 ford galaxie 500데이터 구조 파악하기
# 데이터의 수와 변수는?
dim(car)
## [1] 398 9
# 데이터 수: 398개, 변수: 9개
# 데이터 전체 주고 파악하기: str 함수
str(car)
## 'data.frame': 398 obs. of 9 variables:
## $ mpg : num 18 15 18 16 17 15 14 14 14 15 ...
## $ cyl : int 8 8 8 8 8 8 8 8 8 8 ...
## $ disp : num 307 350 318 304 302 429 454 440 455 390 ...
## $ hp : num 17 35 29 29 24 42 47 46 48 40 ...
## $ wt : int 3504 3693 3436 3433 3449 4341 4354 4312 4425 3850 ...
## $ accler : num 12 11.5 11 12 10.5 10 9 8.5 10 8.5 ...
## $ year : int 70 70 70 70 70 70 70 70 70 70 ...
## $ origin : int 1 1 1 1 1 1 1 1 1 1 ...
## $ carname: chr "chevrolet chevelle malibu" "buick skylark 320" "plymouth satellite" "amc rebel sst" ...
# num: 실수, int: 정수
# 데이터 요약하기: summary 함수
summary(car)
## mpg cyl disp hp wt
## Min. : 9.00 Min. :3.000 Min. : 68.0 Min. : 1.00 Min. :1613
## 1st Qu.:17.50 1st Qu.:4.000 1st Qu.:104.2 1st Qu.:26.00 1st Qu.:2224
## Median :23.00 Median :4.000 Median :148.5 Median :60.50 Median :2804
## Mean :23.51 Mean :5.455 Mean :193.4 Mean :51.39 Mean :2970
## 3rd Qu.:29.00 3rd Qu.:8.000 3rd Qu.:262.0 3rd Qu.:79.00 3rd Qu.:3608
## Max. :46.60 Max. :8.000 Max. :455.0 Max. :94.00 Max. :5140
## accler year origin carname
## Min. : 8.00 Min. :70.00 Min. :1.000 Length:398
## 1st Qu.:13.82 1st Qu.:73.00 1st Qu.:1.000 Class :character
## Median :15.50 Median :76.00 Median :1.000 Mode :character
## Mean :15.57 Mean :76.01 Mean :1.573
## 3rd Qu.:17.18 3rd Qu.:79.00 3rd Qu.:2.000
## Max. :24.80 Max. :82.00 Max. :3.000
# 데이터 요약통계치(빈도 구하기): table 함수
attach(car) # attach를 쓰면 변수에 이름을 안 써도 됨
## The following object is masked from brain:
##
## wt
table(origin)
## origin
## 1 2 3
## 249 70 79
table(year)
## year
## 70 71 72 73 74 75 76 77 78 79 80 81 82
## 29 28 28 40 27 30 34 28 36 29 29 29 31
# 데이터 요약통계치 (평균, 표준편차): mean
mean(mpg)
## [1] 23.51457
mean(hp)
## [1] 51.38945
mean(wt)
## [1] 2970.4254. 데이터 핸들링
dplyr 활용
dplyr: 전처리 과정을 하기 위한 편리한 기능
library(dplyr)
attach(car)
## The following objects are masked from car (pos = 3):
##
## accler, carname, cyl, disp, hp, mpg, origin, wt, year
## The following object is masked from brain:
##
## wt
str(car)
## 'data.frame': 398 obs. of 9 variables:
## $ mpg : num 18 15 18 16 17 15 14 14 14 15 ...
## $ cyl : int 8 8 8 8 8 8 8 8 8 8 ...
## $ disp : num 307 350 318 304 302 429 454 440 455 390 ...
## $ hp : num 17 35 29 29 24 42 47 46 48 40 ...
## $ wt : int 3504 3693 3436 3433 3449 4341 4354 4312 4425 3850 ...
## $ accler : num 12 11.5 11 12 10.5 10 9 8.5 10 8.5 ...
## $ year : int 70 70 70 70 70 70 70 70 70 70 ...
## $ origin : int 1 1 1 1 1 1 1 1 1 1 ...
## $ carname: chr "chevrolet chevelle malibu" "buick skylark 320" "plymouth satellite" "amc rebel sst" ...변수 추출: select
car 데이터에서 mpg, hp 변수만 추출
# Data handling usin "dplyr"
# 1 subset data: selecting a few variables
set1 <- select(car, mpg, hp)
head(set1)
## mpg hp
## 1 18 17
## 2 15 35
## 3 18 29
## 4 16 29
## 5 17 24
## 6 15 42car 데이터에서 mpg로 시작하는 변수를 제외
# 2 subset data: drop variables with -
set2 <- select(car, -starts_with("mpg"))
head(set2)
## cyl disp hp wt accler year origin carname
## 1 8 307 17 3504 12.0 70 1 chevrolet chevelle malibu
## 2 8 350 35 3693 11.5 70 1 buick skylark 320
## 3 8 318 29 3436 11.0 70 1 plymouth satellite
## 4 8 304 29 3433 12.0 70 1 amc rebel sst
## 5 8 302 24 3449 10.5 70 1 ford torino
## 6 8 429 42 4341 10.0 70 1 ford galaxie 500데이터 추출: filter
- 조건에 맞는 데이터 추출: filter(데이터, 변수 조건, …)
car 데이터에서 mpg가 30보다 큰 행 추출
# 3 subset data: filter mpg > 50
set3 <- filter(car, mpg > 30)
head(set3)
## mpg cyl disp hp wt accler year origin carname
## 1 31 4 71 62 1773 19.0 71 3 toyota corolla 1200
## 2 35 4 72 66 1613 18.0 71 3 datsun 1200
## 3 31 4 79 64 1950 19.0 74 3 datsun b210
## 4 32 4 71 62 1836 21.0 74 3 toyota corolla 1200
## 5 31 4 76 53 1649 16.5 74 3 toyota corona
## 6 32 4 83 58 2003 19.0 74 3 datsun 710변수 생성: mutate
- mutate(새로운 변수 이름 = 기존 변수 활용)
- %>% 파이프 연산자: 연산자 사용하여 연결
# create a derived variable
set4 <- car %>%
filter(!is.na(mpg)) %>%
mutate(mpg_km = mpg*1.609)
head(set4)
## mpg cyl disp hp wt accler year origin carname mpg_km
## 1 18 8 307 17 3504 12.0 70 1 chevrolet chevelle malibu 28.962
## 2 15 8 350 35 3693 11.5 70 1 buick skylark 320 24.135
## 3 18 8 318 29 3436 11.0 70 1 plymouth satellite 28.962
## 4 16 8 304 29 3433 12.0 70 1 amc rebel sst 25.744
## 5 17 8 302 24 3449 10.5 70 1 ford torino 27.353
## 6 15 8 429 42 4341 10.0 70 1 ford galaxie 500 24.135
# filter: car 데이터 mpg열의 NA가 아닌 모든 데이터 추출
# mutate: 기존 mpg열을 사용해 새로운 mpg_km열 생성데이터 요약 통계치(평균)
- summarize(mean(변수이름))
# mean and standard deviation
car %>%
summarize(mean(mpg), mean(hp), mean(wt))
## mean(mpg) mean(hp) mean(wt)
## 1 23.51457 51.38945 2970.425
# 몇 개 변수의 평균값 한 번에 구하기
select(car, 1:6) %>%
colMeans() # 데이터를 열로 재구성하여 평균값 구함
## mpg cyl disp hp wt accler
## 23.514573 5.454774 193.425879 51.389447 2970.424623 15.568090백터화 요약치: summarize_all(FUN)
- 열추출하여 기술통계치 구하고 요약치 보기
a1 <- select(car, 1:6) %>% summarize_all(mean)
a2 <- select(car, 1:6) %>% summarize_all(sd)
a3 <- select(car, 1:6) %>% summarize_all(min)
a4 <- select(car, 1:6) %>% summarize_all(max)
table1 <- data.frame(rbind(a1,a2,a3,a4))
rownames(table1) <- c("mean", "sd", "min", "max") # data.frame을 tbl_df로 전환시켰으므로 data.frame으로 원상복귀하여 행 이름을 바꿈
table1
## mpg cyl disp hp wt accler
## mean 23.514573 5.454774 193.4259 51.38945 2970.4246 15.568090
## sd 7.815984 1.701004 104.2698 29.93236 846.8418 2.757689
## min 9.000000 3.000000 68.0000 1.00000 1613.0000 8.000000
## max 46.600000 8.000000 455.0000 94.00000 5140.0000 24.800000그룹별 통계량: group_by
- group_by(변수), summarize(__=FUN()) 그룹별 요약통계량 구하기
# summary statistics by group variable
car %>%
group_by(cyl) %>%
summarize(mean_mpg = mean(mpg), na.rm = TRUE)
## `summarise()` ungrouping output (override with `.groups` argument)
## # A tibble: 5 x 3
## cyl mean_mpg na.rm
## <int> <dbl> <lgl>
## 1 3 20.6 TRUE
## 2 4 29.3 TRUE
## 3 5 27.4 TRUE
## 4 6 20.0 TRUE
## 5 8 15.0 TRUE
# group_by: car 데이터의 cyl열을 그룹으로 묶음
# summarize: cyl그룹의 mpg 평균을 구함
# na.rm = TURE: 통계 분석 시 결측값을 제외- 퀴즈
height <- c(165, 170, 155, 185)
weight <- c(55, 65, 50, 110)
gender <- c("Female", "Male", "Female", "Male")
df <- data.frame(height, weight, gender)
df
## height weight gender
## 1 165 55 Female
## 2 170 65 Male
## 3 155 50 Female
## 4 185 110 Male
df %>%
group_by(height) %>%
summarize(result = mean(gender))
## Warning in mean.default(gender): argument is not numeric or logical: returning
## NA
## Warning in mean.default(gender): argument is not numeric or logical: returning
## NA
## Warning in mean.default(gender): argument is not numeric or logical: returning
## NA
## Warning in mean.default(gender): argument is not numeric or logical: returning
## NA
## `summarise()` ungrouping output (override with `.groups` argument)
## # A tibble: 4 x 2
## height result
## <dbl> <dbl>
## 1 155 NA
## 2 165 NA
## 3 170 NA
## 4 185 NA
summarize(group_by(df, gender), result=mean(height))
## `summarise()` ungrouping output (override with `.groups` argument)
## # A tibble: 2 x 2
## gender result
## <chr> <dbl>
## 1 Female 160
## 2 Male 178.
filter(df, gender = c("Male", "Female")) %>%
summarize(result = mean())
## Error: Problem with `filter()` input `..1`.
## x Input `..1` is named.
## i This usually means that you've used `=` instead of `==`.
## i Did you mean `gender == c("Male", "Female")`?
df %>%
select(height) %>%
summarize(result = mean(gender))
## Warning in mean.default(gender): argument is not numeric or logical: returning
## NA
## result
## 1 NA